
Nearly all Agile methodologies rely on some form of iterative development. It would be difficult to do otherwise while valuing “Working software over comprehensive documentation” or “Responding to change over following a plan” as called for in the Agile Manifesto.
However, iterative development often requires a greater degree of skill than more traditional methods. Without care it can quickly devolve into cowboy coding or “waterfall in disguise”. Do you suspect your team might be guilty of this at times? Let’s discuss how to really get the most out of iterative development.
Iterative Development Defined
For the purposes of this article, lets define iterative development as any process which incrementally delivers working software while remaining open to change. This is similar to what you’ll find at Wikipedia and other sources. We can contrast iterative methods with the waterfall approach, which generally is not expected to deliver value until the project is complete.
Strengths
Iterative development has several natural strengths:
- Customers derive value from early versions
- Developers and testers de-risk critical element early
- Requirements and designs can be progressively elaborated, factoring in early experience from all stakeholders
Challenges
Unfortunately, iterative development is a two-edged sword. Requirements can change without converging and designs can be found insufficient to support the next iteration.
However, with skills in two key areas, you can take control of your iterative process:
- Planning
- Extensible Development
Planning
When discussing iterative development, I like to use an analogy: a trip from my home town of Trail, BC to Calgary.
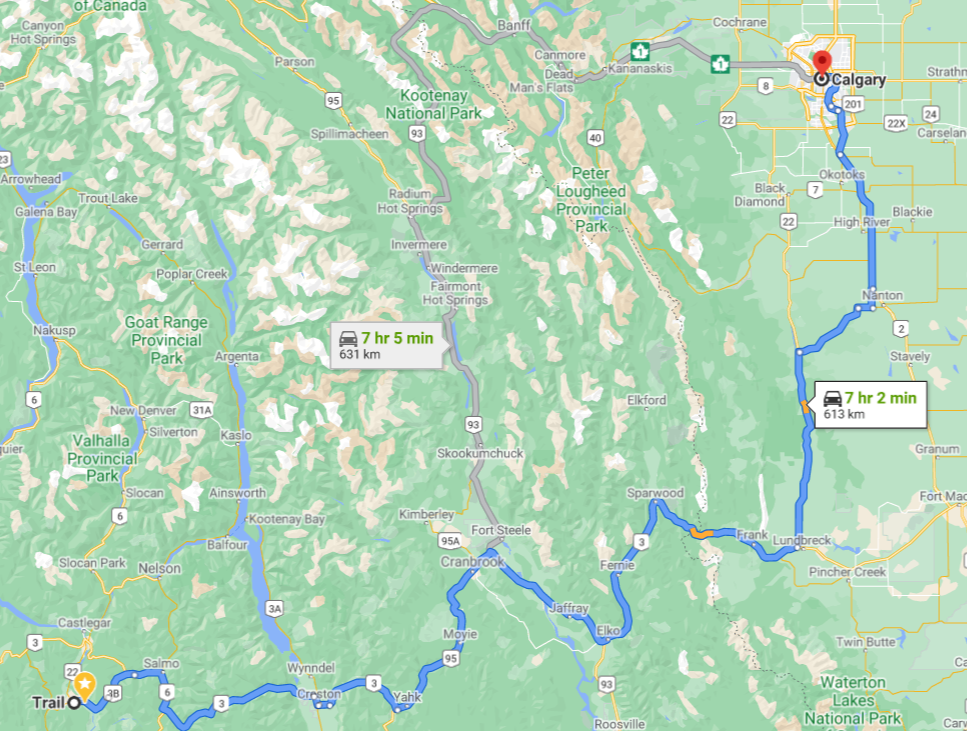
How might we plan this trip?
If you followed a greedy algorithm and took the most north-easterly fork at each junction you’d quickly end up at a dead end. Even if you stuck to the major highways, you’d find yourself on the wrong side of the Purcell Mountains: a 2 hour detour.
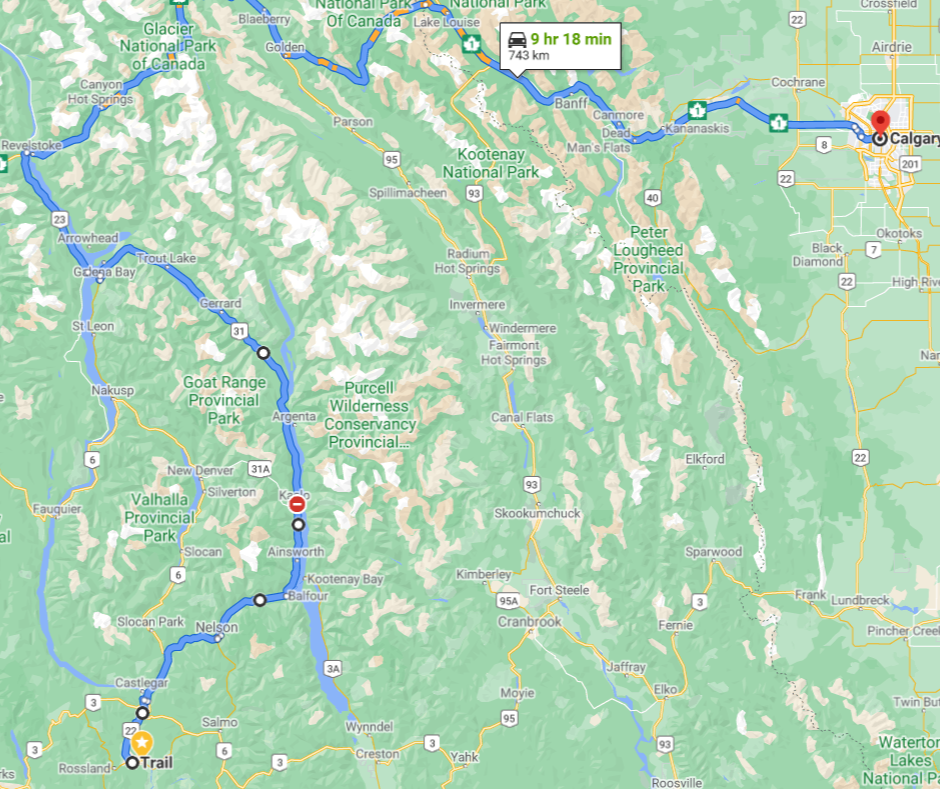
You already knew that a greedy algorithm is not the way to solve pathfinding on a map. This is exactly what we’re doing if we work one iteration at a time, with no thought for the future. We’re at risk of hitting a dead-end and having to throw away work. Even if we avoid that, we’re likely to deviate far from the optimal route.
The obvious answer to this is to plan up-front, waterfall style. Since we have a good map, this will get you there just fine most days. This can be a reasonable plan for projects that are small sized and well understood.
To highlight the problem with the waterfall approach, let’s continue the road-trip analogy. The most direct route takes you through two mountain passes: the Salmo-Creston and the Crowsnest Pass. If you happen to be making this trip in the winter, each of these passes is subject to closures ranging from an hour to several days.
The answer, in the case of navigation, is to check the state of each pass pass when you leave in the morning and again as you cross the last fork in the road before committing to that pass, rather than choosing a detour.
For real projects, it’s usually not possible to plan every possibility. This is where iterative development comes in:
Progressive Elaboration
To quote the PMBOK 6th ed. “Adaptive life cycles… develop a set of high-level plans for the initial requirements and progressively elaborate requirements to an appropriate level of detail for the planning cycle.”
That is, in addition to detailed planning for the current iteration, you should have a high-level plan for the overall project.
The high-level plan differs from a traditional waterfall plan in that it only exists at the high level. This makes it a much smaller and lighter document to create and update. However, the plan does include the broad outlines and the end goal, as well as major objectives along the way.
For large projects the high level plan itself will be iteratively updated. More distant portions start in broad outlines then gain detail until they are incorporated into a project iteration. The right level of detail will vary based on other considerations; in general though:
- More Technical Risk → More Detailed Planning
- More Change Risk → Less Detailed Planning
Minimize Technical Risk…. With Scheduling?
We know generally where we want to go, and we are going to iterate to get there. So which features should go into the first iteration? The second?
“Whatever the customer wants most” I hear the sales folks say.
“Whatever part is easiest” I hear from junior developers.
Putting these two things together gets iterative projects off to a fast start. It puts cool features into customer’s hands. However, it’s often a trap. By doing the easy parts first, you defer technical risk and, worse, the risk grows. If some feature can’t be implemented as you expect, the sooner you find out the less impact it will have on the overall project. Therefore I advocate a slightly different approach:
Prioritize features by (customer value) x (technical risk)
You don’t need to get too granular. In most cases this is almost the same as working in order by customer value, except that key technical challenges will be pulled into early iterations.
This also doesn’t mean you need to implement an architecture up front that handles every conceivable future edge case. You can often plan for the future without coding for it. On the other hand, if the technical risks are large enough, it may be better to address them with prototypes before starting iterative development.
Extensible Development
So far we’ve been talking about what the managers and leaders need to do to help an interactive development project succeed. What about the software architects and developers? Does iterative code look different?
It does.
Marginal designs that would be good-enough for a waterfall project are likely to fail in an iterative one.
In a waterfall project, your code just needs to meet the specification. In an iterative project, your code will also need to support loosely defined future objectives. Brittle code will eventually cause problems on any project, but in an iterative one it may prevent you from even getting to version 1.0.
The answer is extensibility, the ability for your code to be extended in new ways. Fortunately developers have been working on this for many years and have developed numerous principles to help achieve this goal. I won’t try to cover them all here, but I will reference some that I’ve found most valuable:
- DRY – Don’t Repeat Yourself –Hunt & Thomas
- SOLID – Robert Martin
- Single Responsibility – a class should have only one reason to change
- Open-Closed – open for extension, but closed for modification
- Liskov Substitution – subtypes must be substitutable for base types
- Interface Segregation – clients not forced to depend on methods they don’t use
- Dependency Inversion – don’t depend on (volatile) implementation details
- Be concise
- Ensure most of your code is actually solving the business problem, not setting up abstractions. That is, the principals above can be taken too far, stay focused on the big picture.
- Adopt concise coding standards – while ambiguity and obscure coding is a problem, excessively verbose code also slows down developer understanding.
- Anticipate change in general, rather than trying to anticipate specific changes.
Key Points
- Iterative development is a better plan that waterfall development for most software projects
- Some long-term planning is still required to avoid dead-ends
- Resolve technical risks early, either with prototypes or by addressing them in early iterations
- Good software design, particularly extensibility, is essential to successful iterative development
Discuss
Use the comments section below to share your successes, and let me know what you think. Do you have some great ideas I didn’t mention above?
The forum is moderated and your first post may not appear until it has been manually approved.